Synicix ML Pipeline¶
Prerequisites¶
- Datajoint
- Docker
- K8
- Pytorch
Introduction:¶
Synicix ML Pipeline is a pytorch based machine learning pipeline built to facilitate training machine learning models on various dataset with different training configuration as well provide various other useful tools such as fp16 mixed precision training.
In order to keep improving the pipeline, please file bugs and feature request to the Github Repo under the Other Resrouces section
Overview on Architecture¶
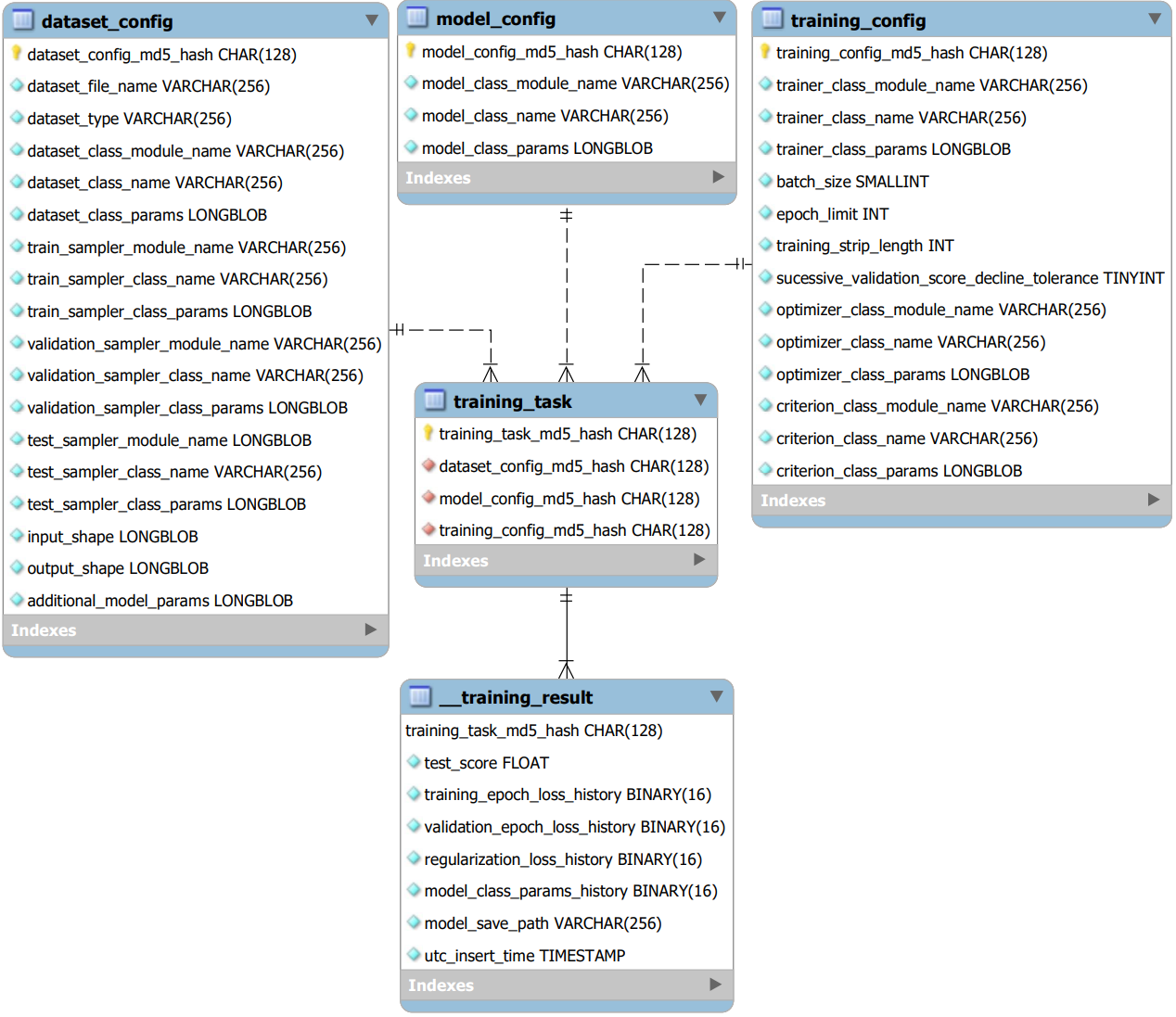
DatasetConfig, ModelConfig, TrainingConfig¶
At the core of the pipeline is Dataset Config, Models Config, and Training Config shown in their respective tables above. These core tables handles the defining what dataset and model to use and how to train as the name suggesst
TrainingTask¶
Following the three core tables is the Training Task table which serves as a table indiciating what combination of Dataset Config, Model Config, and Training Config should be fed thorugh the pipeline. Typically this is use to restrict to a subset of all possiable combination between the 3 core tables.
TrainingResult¶
After that we have the Training Result table which handles storing the training of every combination in the Training Task table.
DatasetConfig, ModelConfig, TrainingConfig, and TrainingTask are dj.Manual Tables, while TrainingResult is dj.Computed
Handling of Abstraction¶
In order to deal the possability various needs and use cases the pipeline was built with heavy abstraction in mind via the import module libaray provided by python.
Due to this, you will often see table definition requiring model_class_name and class_name which basically tells the pipeline what class to import from where. Futher details will be covered the following sections.
Using the Pipeline¶
Jupyter Notebook example:¶
https://github.com/cajal/SynicixMLPipeline/blob/master/Pipeline%20Configuration.ipynb
Note: however this only shows the inserting and not how to create your own dataset and models to be used in this pipeline, as such the following section will go into more detail behind that.
Directory Setup¶
Before running any code the pipeline typically requires certain global variable paths to be defined.
- dj.config[‘store’][‘external_training_results’]: Where to store the external blobs for the TrainingResult table
- dataset_dir: Where the dataset files are stored
- dataset_cache_dir: Where to cache the dataset files to the local computer when training
- model_save_dir: Where to save the model checkpoint files to
Here is example:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | import os
import datajoint as dj
if os.name == 'nt':
dj.config['stores'] = dict(external_training_result = dict(protocol='file', location='\\mnt\\scratch07\\external'))
dataset_dir = '\\\\at-storage3.ad.bcm.edu\\scratch07\\synicix_dev\\datasets\\'
dataset_cache_dir = 'C:\\\\dataset_cache\\'
model_save_dir = '\\\\at-storage3.ad.bcm.edu\\scratch07\\synicix_dev\\model_storage\\'
elif os.name == 'posix':
dj.config['stores'] = dict(external_training_result = dict(protocol='file', location='/mnt/scratch07/external/training_result'))
dataset_dir = '/mnt/scratch07/synicix_dev/datasets/'
dataset_cache_dir = 'dataset_cache/'
model_save_dir = '/mnt/scratch07/synicix_dev/model_storage/'
|
DatasetConfig¶
A dj.Manual table class that handle the storage dataset configs with details on what dataset class and params to load that dataset and dataloader with.
Definition¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | definition = """
dataset_config_md5_hash : char(128)
---
dataset_file_name : varchar(256)
dataset_type : varchar(256)
dataset_class_module_name : varchar(256)
dataset_class_name : varchar(256)
dataset_class_params : longblob
train_sampler_module_name : varchar(256)
train_sampler_class_name : varchar(256)
train_sampler_class_params : longblob
validation_sampler_module_name : varchar(256)
validation_sampler_class_name : varchar(256)
validation_sampler_class_params : longblob
test_sampler_module_name : longblob
test_sampler_class_name : varchar(256)
test_sampler_class_params : longblob
input_shape : longblob
output_shape : longblob
additional_model_params : longblob
"""
|
Additional Details on the Attributes¶
- dataset_class_module_name, dataset_class_name, dataset_class_params: Details what pytorch based dataset_class it should import (user defined) [REQUIRED]
- (train, validation, test) _sampler_module_name, _sampler_class_name, _sampler_class_params: What pytorch sampler class should be passed into the respective dataloader (user defined) [If not defined it will default to pytroch default dataloader Sampler]
- input_shape, output_shape: These are computed via the validation dataset and is passed to the model during the model creation [Requires validation examples]
- additional_model_params: Obatin from calling get_additional_model_params from the dataset class [No additional params should be defined as dict()]
Additional Notes on Dataloader Default Beheavior¶
- By default, if sampler for train is not defined then shuffle will be set to True, else False
- By default, if sampler for (validation/test) is not defined then shuffle will be set to False
Implementation of a Dataset Class¶
Dataset Config expects a pytorch base dataset class with a few additional requirements:
The following functions need to be defined:
- __len___(self): Pytorch Dataset requirement
- __getitem__(self, index):: Pytorch Dataset requirement
- get_additional_model_params(self): DatasetConfig requirement, use to define additional_model_params
Example: synicix_ml_pipeline.dataset_classes.NeuroDataDataset module
Inserting into DatasetConfig¶
DatasetConfig has a insert_tuples functions to handle the computation of md5_hash as well other infomation such as input_shape and etc. As such one should always use this function to insert into the table
Below is an example of how to insert multiple DatasetConfigs:
(NOTE: Please note that dataset_dir and dataset_cache_dir must be defined ahead of time):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | # Get all dataset file name under the dataset_dir and insert them
dataset_file_names = os.listdir(dataset_dir)
tuple_dicts_to_insert = []
for dataset_file_name in dataset_file_names:
tuple_dict = dict(
dataset_file_name = dataset_file_name,
dataset_type = 'NeuroDataDataset',
dataset_class_module_name = 'synicix_ml_pipeline.dataset_classes.NeuroDataDataset',
dataset_class_name = 'NeuroDataDataset',
dataset_class_params = dict(mode='full-encoding'),
train_sampler_module_name = '',
train_sampler_class_name = '',
train_sampler_class_params = dict(),
validation_sampler_module_name = '',
validation_sampler_class_name = '',
validation_sampler_class_params = dict(),
test_sampler_module_name = '',
test_sampler_class_name = '',
test_sampler_class_params = dict(),
)
tuple_dicts_to_insert.append(tuple_dict)
dataset_config.insert_tuples(tuple_dicts_to_insert)
|
ModelConfig¶
A dj.Manual table class that handle the storage of pytorch models definition along with some helper function to help load the models
Definition¶
1 2 3 4 5 6 7 | definition = """
model_config_md5_hash : char(128) # MD5 Hash of network_class_name + network_module_code
---
model_class_module_name : varchar(256)
model_class_name : varchar(256) # Class name of the network
model_class_params : longblob
"""
|
Implementation of a Model Class¶
The pipeline expects the standard pytorch model with a few additional requirements
The following functions need to be defined:
- __init__(self, input_shape, output_shape): Pytorch Dataset where input_shape and output_shape are required by the pipeline
- forward(self, x):: Pytorch Dataset requirement, must return two variables: output, regularlization loss
Inserting into ModelConfig¶
ModelConfig has a insert_tuples functions to handle the computation of md5_hash, as such one should always use this function to insert into the table.
Below is an example of how to insert into ModelConfig:
1 2 3 4 5 6 7 8 9 10 11 | tuple_dicts = []
tuple_dict = dict(
model_class_module_name='synicix_ml_pipeline.models.SimpleMLP',
model_class_name='SimpleMLP',
model_class_params=dict(num_hidden_layers=1, hidden_size=1000, l1_loss_lamda=0.0, l2_loss_lamda=0.0)
)
tuple_dicts.append(tuple_dict)
model_config.insert_tuples(tuple_dicts)
|
TrainingConfig¶
Definition¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | definition = """
training_config_md5_hash : char(128) # MD5 Hash of attribute below
---
trainer_class_module_name : varchar(256)
trainer_class_name : varchar(256)
trainer_class_params : longblob
batch_size : smallint unsigned
epoch_limit : int unsigned
optimizer_class_module_name : varchar(256)
optimizer_class_name : varchar(256)
optimizer_class_params : longblob
criterion_class_module_name : varchar(256)
criterion_class_name : varchar(256)
criterion_class_params : longblob
"""
|
Additional Details on the Attributes¶
- trainer_class_module_name, trainer_class_name, trainer_class_params: Details what trainer it should import and use, default will be NNTrainer located under synicix_ml_pipeline/trainers/NNTrainer.py (user defined) [REQUIRED]
- optimizer_class_module_name, optimizer_class_name, optimizer_class_params: Details what pytorch based optimizer it should import and use (user defined) [REQUIRED]
- criterion_class_module_name, criterion_class_name, criterion_class_params: Details what pytorch based criterion it should import and use (user defined) [REQUIRED]
Implementing a Trainer Class¶
Required init parameters:
- train_dataloader (pytorch dataloader)
- validation_dataloader (pytorch dataloader)
- test_dataloader (pytorch dataloader)
- device (pytorch device)
- model_class (user defined)
- model_class_params (user defined dict)
- optimizer_class (user defined)
- optimizer_class_params (user defined dict)
- criterion_class (user defined)
- criterion_class_params (user defined dict)
- model_save_path (str)
- max_epoch (int)
Required functions:
- train(self): Function to start training process
- validate(self): Function to run the validate dataset
- evaluate(self, return_outputs_targets_and_loss=False): Function to run the test dataset and return loss or a dict of (outputs, targets, and loss)
- load_best_performing_model(self): Load best the load best performing model once training is done
TrainingTask¶
This table serves as a subset of all possiable Dataset, Model and Training Config combination. Whatever is inserted here will be trained with its result recorded in TrainnigResult
Definition¶
1 2 3 4 5 6 7 | definition = """
training_task_md5_hash : char(128) # MD5 Hash of attribute below
---
-> DatasetConfig
-> ModelConfig
-> TrainingConfig
"""
|
Inserting into TrainingTask¶
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | dataset_config_keys = (DatasetConfig).fetch('KEY')
model_config_keys =(ModelConfig).fetch('KEY')
training_config_keys = (TrainingConfig).fetch('KEY')
tuple_dicts = []
# Insert the possiable combination base on the restrictions above
for dataset_config_key in dataset_config_keys:
for model_config_key in model_config_keys:
for training_config_key in training_config_keys:
tuple_dict = dict()
tuple_dict.update(dataset_config_key)
tuple_dict.update(model_config_key)
tuple_dict.update(training_config_key)
tuple_dicts.append(tuple_dict)
training_task.insert_tuple(tuple_dicts)
|
TrainingResult¶
Definition¶
1 2 3 4 5 6 7 8 9 10 11 | definition = """
-> TrainingTask
---
test_score : float
training_epoch_loss_history : blob@external_training_result
validation_epoch_loss_history : blob@external_training_result
regularization_loss_history : blob@external_training_result
model_class_params_history : blob@external_training_result
model_save_path : varchar(256)
utc_insert_time = CURRENT_TIMESTAMP : timestamp
"""
|
Populating TrainingResult:¶
TrainingResult will require dataset_dir, dataset_cache_dir, model_save_dir, and num_workers to be defined, where num_workers is number of dataloaders threads.
Typical usesage of populating TrainingResult is done via a .py script and K8
training_script.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | import os
import sys
import datajoint as dj
from synicix_ml_pipeline.datajoint_tables.TrainingResult import TrainingResult
if __name__ == '__main__':
if os.name == 'nt':
dj.config['stores'] = dict(external_training_resul = dict(protocol='file', location='\\mnt\\scratch07\\external'))
dataset_dir = '\\\\at-storage3.ad.bcm.edu\\scratch07\\synicix_dev\\datasets\\'
dataset_cache_dir = 'C:\\\\dataset_cache\\'
model_save_dir = '\\\\at-storage3.ad.bcm.edu\\scratch07\\synicix_dev\\model_storage\\'
elif os.name == 'posix':
dj.config['stores'] = dict(external_training_result = dict(protocol='file', location='/mnt/scratch07/external/training_result'))
dataset_dir = '/mnt/scratch07/synicix_dev/datasets/'
dataset_cache_dir = 'dataset_cache/'
model_save_dir = '/mnt/scratch07/synicix_dev/model_storage/'
# Get num_workers from args
num_workers = int(sys.argv[1])
# Create the TrainingResult instance
training_result = TrainingResult(dataset_dir=dataset_dir, dataset_cache_dir=dataset_cache_dir, model_save_dir=model_save_dir, num_workers=num_workers)
# Being populating
training_result.populate(reserve_jobs=True, order='random')
|
K8 population yaml file
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 | apiVersion: batch/v1 # Jobs Default K8 API
kind: Job # This tells kubernetes what kind of class it is working with
metadata:
name: synicix-ml-pipeline # Name of the Job
spec:
parallelism: 110 #
template: # Pod Templete
spec:
restartPolicy: Never # Options are OnFailure, and Never.
hostNetwork: true # This option will allow the pod to use the host network for internet access
tolerations: # This toleration allows the pod to be schedule onto gpu-only pod machines, remove this if you are not using gpu
- key: "gpu"
operator: "Equal"
value: "true"
effect: "NoSchedule"
volumes:
- name: mnt
hostPath:
path: /mnt # Directory on the host machine to be mounted
affinity: # Affinity to select certain nodes with 11GB, 12GB, or 24GB memory
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # Require nodes to have this label
nodeSelectorTerms:
- matchExpressions:
- key: gpu_mem_size # Target label is gpu_mem_size
operator: In # Key must have one of the following values
values:
- 8GB
- 11GB
- 12GB
- 24GB
- 32GB
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
preference:
matchExpressions:
- key: tensor_cores
operator: In
values:
- "true"
containers: # Container Level
- name: synicix-ml-pipeline # Container name (Can be set to whatever)
image: synicix/pytorch-fp16-base:latest # Docker Image hosted on Docker Hub
resources:
limits:
nvidia.com/gpu: 1 # requesting 1 GPUs
volumeMounts: # Container reference to volumes define above
- name: mnt # Name of the volume define above
mountPath: /mnt # Location of where to mount it in the container
env: # This section refers to secrets created under the user namespace and set them as enviorment variables
- name: DJ_HOST
valueFrom:
secretKeyRef:
name: datajoint-credentials
key: DJ_HOST
- name: DJ_USER
valueFrom:
secretKeyRef:
name: datajoint-credentials
key: DJ_USER
- name: DJ_PASS
valueFrom:
secretKeyRef:
name: datajoint-credentials
key: DJ_PASS
- name: GITHUB_USERNAME
valueFrom:
secretKeyRef:
name: github-credentials
key: GITHUB_USERNAME
- name: GITHUB_PASSWORD
valueFrom:
secretKeyRef:
name: github-credentials
key: GITHUB_PASSWORD
command: ["/bin/bash"] # Entry point for the container
args: ["-c", "git clone https://$(GITHUB_USERNAME):$(GITHUB_PASSWORD)@github.com/Synicix/SynicixMLPipeline.git \
&& pip3 install /SynicixMLPipeline \
&& python3 -u /SynicixMLPipeline/K8/TrainingDeployment/training_script.py 0"] # sh commands to clone and run python script
|